
EmbodiedHead: Real-Time Listening and Speaking Avatar for Conversational Agents
Author information is temporarily withheld for anonymous review.
Interactive Demo
Try the live EmbodiedHead system directly in the browser. You can chat with EmbodiedHead powered by Qwen.
If the interactive demo below is temporarily unavailable, you can still try the full experience at https://www.embodiedhead.xyz/.
实时渲染窗口
未连接
WS: -
缓冲帧: -
状态: idle
Abstract
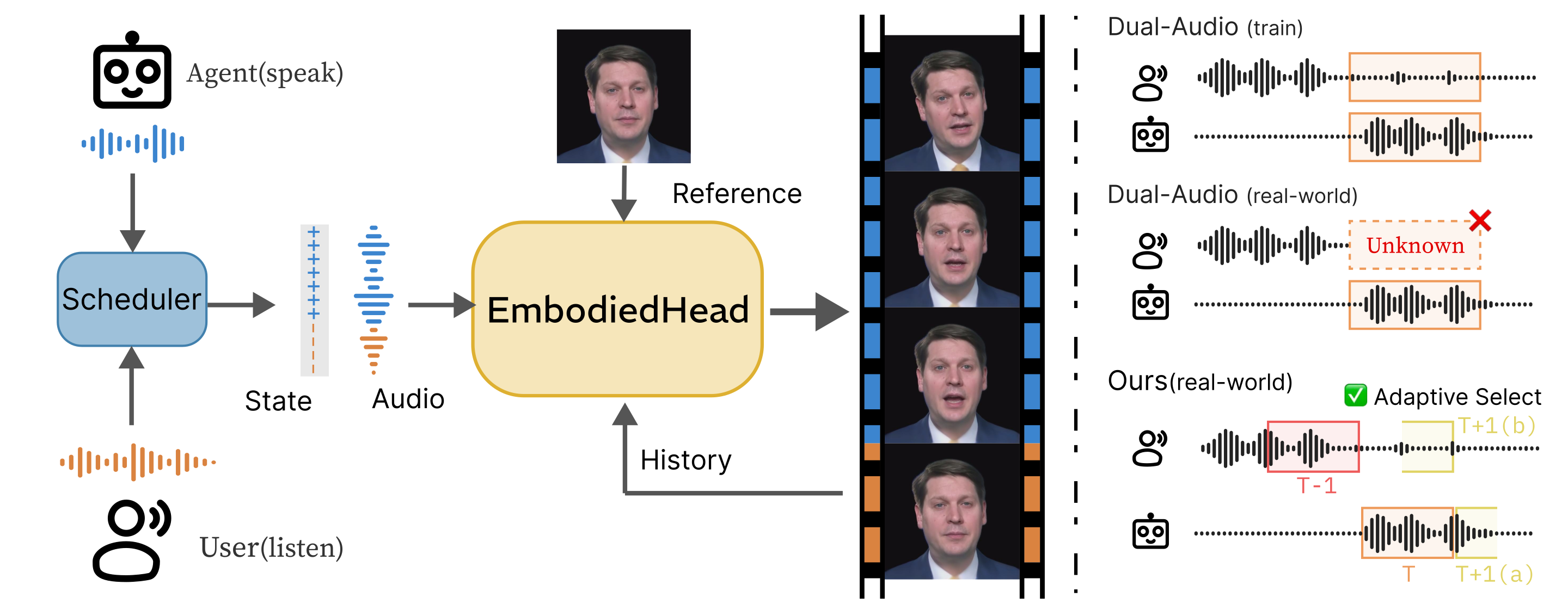
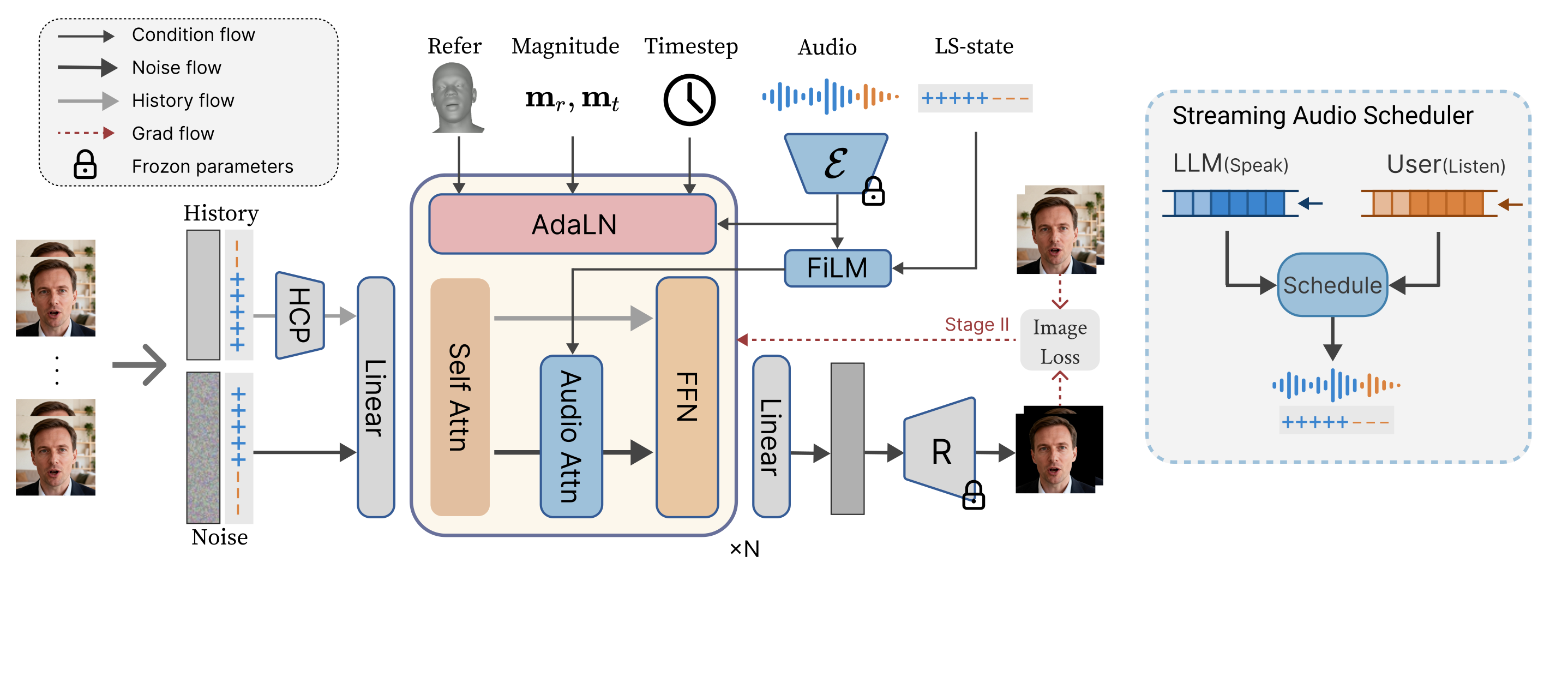
We present EmbodiedHead, a speech-driven talking-head framework that equips LLMs with real-time visual avatars for conversation. A practical embodied avatar must achieve real-time generation, unified listening-speaking behavior, and high rendered visual quality simultaneously. Our framework couples the first Rectified-Flow Diffusion Transformer (DiT) for this task with a differentiable renderer, enabling diverse, high-fidelity generation in as few as four sampling steps. Prior listening-speaking methods rely on dual-stream audio, introducing an interlocutor look-ahead dependency incompatible with causal user–LLM interaction. We instead adopt a single-stream interface with explicit per-frame listening-speaking state conditioning and a Streaming Audio Scheduler, suppressing spurious mouth motion during listening while enabling seamless turn-taking. A two-stage training scheme of coefficient-space pretraining and joint image-domain refinement further closes the gap between motion-level supervision and rendered quality. Extensive experiments demonstrate state-of-the-art visual quality and motion fidelity in both speaking and listening scenarios.
Overview
EmbodiedHead Results
High-fidelity and Liveliness







Comparison



Chatting with EmbodiedHead
BibTeX
@misc{anonymous2026embodiedhead,
title = {EmbodiedHead: Real-Time Listening and Speaking Avatar for Conversational Agents},
author = {Anonymous Authors},
year = {2026},
note = {Author information withheld for anonymous review},
eprint = {2604.17211},
archivePrefix = {arXiv},
url = {https://arxiv.org/abs/2604.17211}
}